11 Chunking Strategies for RAG — Simplified & Visualized

Retrieval-Augmented Generation (RAG) combines pre-trained language models with information retrieval systems to produce more accurate and contextually relevant responses. By fetching pertinent information from external documents, RAG enhances the model’s ability to handle queries beyond its training data.
A critical component of RAG is the chunking process, where large documents are divided into smaller, more manageable pieces called “chunks.” These chunks are then indexed and used during the retrieval phase to provide contextually relevant information to the language model.
Why Chunking Matters
Chunking serves multiple purposes in RAG:
- Efficiency: Smaller chunks reduce computational overhead during retrieval.
- Relevance: Precise chunks increase the likelihood of retrieving relevant information.
- Context Preservation: Proper chunking maintains the integrity of the information, ensuring coherent responses.
However, inappropriate chunking can lead to:
- Loss of Context: Breaking information at arbitrary points can disrupt meaning.
- Redundancy: Overlapping chunks may introduce repetitive information.
- Inconsistency: Variable chunk sizes can complicate retrieval and indexing.
Overview of Chunking Strategies
Chunking strategies vary based on how they divide the text and the level of context they preserve. The main strategies include:
- Fixed-Length Chunking
- Sentence-Based Chunking
- Paragraph-Based Chunking
- Sliding Window Chunking
- Semantic Chunking
- Recursive Chunking
- Context-Enriched Chunking
- Modality-Specific Chunking
- Agentic Chunking
- Subdocument Chunking
- Hybrid Chunking
Each method offers unique advantages and is suited to specific use cases. Lets understand each of this chunking methods in detail, compare different chunking strategies, how to choose right chunking strategy and understand best practices to implement chunking in RAG.
Detailed Exploration of Chunking Methods
Fixed-Length Chunking
How it works: Divides text into chunks of a predefined length, typically based on tokens or characters.

Best for: Simple documents, FAQs, or when processing speed is a priority.
Advantages:
- Simplicity: Easy to implement without complex algorithms.
- Uniformity: Produces consistent chunk sizes, simplifying indexing.
Challenges:
- Context Loss: May split sentences or ideas, leading to incomplete information.
- Relevance Issues: Critical information might span multiple chunks, reducing retrieval effectiveness.
Implementation Tips:
- Choose an appropriate chunk size that balances context and efficiency.
- Consider combining with overlapping windows to mitigate context loss.
Sentence-Based Chunking
How it works: Splits text at sentence boundaries, ensuring each chunk is a complete thought.

Best for: Short, direct responses like customer queries or conversational AI.
Advantages:
- Context Preservation: Maintains the integrity of individual sentences.
- Ease of Implementation: Utilizes natural language processing (NLP) tools for sentence detection.
Challenges:
- Limited Context: Single sentences may lack sufficient context for complex queries.
- Variable Length: Sentence lengths can vary, leading to inconsistent chunk sizes.
Implementation Tips:
- Use NLP libraries for accurate sentence boundary detection.
- Combine multiple sentences if they are short to create a more substantial chunk.
Paragraph-Based Chunking
How it works: Splits documents into paragraphs, which often encapsulate a complete idea or topic.

Best for: Structured documents like articles, reports, or essays.
Advantages:
- Richer Context: Provides more information than sentence-based chunks.
- Logical Division: Aligns with the natural structure of the text.
Challenges:
- Inconsistent Sizes: Paragraph lengths can vary widely.
- Token Limits: Large paragraphs may exceed token limitations of the model.
Implementation Tips:
- Monitor chunk sizes to ensure they stay within acceptable token limits.
- If necessary, split large paragraphs further while trying to maintain context.
Are you preparing for Gen AI/LLM interview ? Look for our LLM Interview preparation Course
- 120+ Questions spanning 14 categories & Real Case Studies
- Curated 100+ assessments for each category
- Well-researched real-world interview questions based on FAANG & Fortune 500 companies
- Focus on Visual learning
- Certificate of completion
50% off Coupon Code — LLM50
Link for the course :
Sliding Window Chunking
How it works: Creates overlapping chunks by sliding a window over the text, ensuring adjacent chunks share content.

Best for: Documents where maintaining context across sections is critical, such as legal or medical texts.
Advantages:
- Context Continuity: Overlaps help preserve the flow of information.
- Improved Retrieval: Increases the chances that relevant information is included in the retrieved chunks.
Challenges:
- Redundancy: Overlapping content can lead to duplicate information.
- Computational Cost: More chunks mean increased processing and storage requirements.
Implementation Tips:
- Optimize the window size and overlap based on the document’s nature.
- Use deduplication techniques during retrieval to handle redundancy.
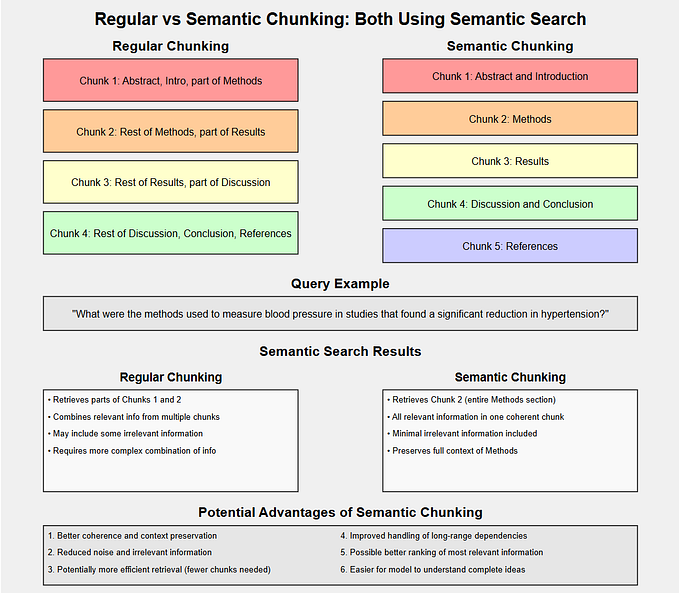
Semantic Chunking
How it works: Utilizes embeddings or machine learning models to split text based on semantic meaning, ensuring each chunk is cohesive in topic or idea.

Best for: Complex queries requiring deep understanding, such as technical manuals or academic papers.
Advantages:
- Contextual Relevance: Chunks are meaningfully grouped, improving retrieval accuracy.
- Flexibility: Adapts to the text’s inherent structure and content.
Challenges:
- Complexity: Requires advanced NLP models and computational resources.
- Processing Time: Semantic analysis can be time-consuming.
Implementation Tips:
- Leverage pre-trained models for semantic segmentation.
- Balance between computational cost and the granularity of semantic chunks.
Recursive Chunking
How it works: Breaks down text progressively into smaller chunks using hierarchical delimiters like headings, subheadings, paragraphs, and sentences.

Best for: Large, hierarchically structured documents like books or extensive reports.
Advantages:
- Hierarchical Context: Maintains the document’s structural relationships.
- Scalability: Effective for very large texts.
Challenges:
- Complex Implementation: Requires handling multiple levels of text structure.
- Potential Context Loss: Smallest chunks may still lose context if not managed properly.
Implementation Tips:
- Use document structure (like HTML tags) to identify hierarchical levels.
- Store metadata about each chunk’s position in the hierarchy for context during retrieval.
Context-Enriched Chunking
How it works: Enriches each chunk by adding summaries or metadata from surrounding chunks, maintaining context across sequences.

Best for: Long documents where coherence across many chunks is essential.
Advantages:
- Enhanced Context: Provides additional information without increasing chunk size significantly.
- Improved Coherence: Helps the model generate more accurate and contextually appropriate responses.
Challenges:
- Complexity: Requires additional processing to generate summaries or metadata.
- Storage Overhead: Enriched chunks consume more storage space.
Implementation Tips:
- Generate concise summaries to minimize additional token usage.
- Consider including key terms or concepts as metadata instead of full summaries.
Modality-Specific Chunking
How it works: Handles different content types (text, tables, images) separately, chunking each according to its nature.

Best for: Mixed-media documents like scientific papers or user manuals.
Advantages:
- Tailored Approach: Optimizes chunking for each content type.
- Improved Accuracy: Specialized processing can enhance retrieval effectiveness.
Challenges:
- Implementation Complexity: Requires custom logic for each modality.
- Integration Difficulty: Combining information from different modalities during retrieval can be challenging.
Implementation Tips:
- Use OCR for images containing text.
- Convert tables into structured data formats.
- Maintain a consistent indexing system across modalities.
Agentic Chunking
How it works: Employs a large language model (LLM) to analyze the text and suggest chunk boundaries based on content structure and semantics.

Best for: Complex documents where preserving meaning and context is critical.
Advantages:
- Intelligent Segmentation: Leverages the LLM’s understanding to create meaningful chunks.
- Adaptive: Can handle diverse and unstructured content effectively.
Challenges:
- Computationally Intensive: Requires significant resources to process the entire document.
- Cost: May not be practical for large-scale applications due to computational expenses.
Implementation Tips:
- Use agentic chunking selectively for critical documents.
- Optimize LLM prompts to focus on identifying logical chunk boundaries efficiently.
Subdocument Chunking
How it works: Summarizes entire documents or large sections and attaches these summaries to individual chunks as metadata.

Best for: Enhancing retrieval efficiency in extensive document collections.
Advantages:
- Hierarchical Retrieval: Allows retrieval systems to operate at multiple context levels.
- Contextual Depth: Provides additional layers of information for the model.
Challenges:
- Additional Processing: Requires generating and managing summaries.
- Metadata Management: Increases the complexity of the indexing system.
Implementation Tips:
- Automate the summarization process using NLP techniques.
- Store summaries efficiently to minimize storage impacts.
Hybrid Chunking
How it works: Combines multiple chunking strategies to adapt dynamically to different query types or document structures.

Best for: Versatile systems handling a wide range of queries and document types.
Advantages:
- Flexibility: Can switch strategies based on content and requirements.
- Optimized Performance: Balances speed and accuracy across use cases.
Challenges:
- Complex Logic: Requires sophisticated decision-making algorithms.
- Maintenance: More components can increase the potential for errors.
Implementation Tips:
- Develop criteria for selecting chunking strategies (e.g., document type, query complexity).
- Test and validate the hybrid approach extensively to ensure reliability.
Comparative Analysis of Chunking Strategies
AgenticRAG with LlamaIndex Course
Look into our AgenticRAG with LlamaIndex Course with 5 real-time case studies.
- RAG fundamentals through practical case studies
- Learn advanced AgenticRAG techniques, including:
- Routing agents
- Query planning agents
- Structure planning agents
- ReAct agent with a human in the loop - Dive into 5 real-time case studies with code walkthroughs
Choosing the Right Chunking Strategy
Selecting the appropriate chunking strategy depends on several factors:
- Document Type: Structured vs. unstructured, length, and modality.
- Query Complexity: Simple FAQs vs. complex technical inquiries.
- Resource Availability: Computational power and time constraints.
- Desired Outcome: Speed vs. accuracy vs. context preservation.
Guidelines:
- For Speed: Use fixed-length or sentence-based chunking.
- For Context: Opt for sliding window, semantic, or context-enriched chunking.
- For Mixed Content: Employ modality-specific or hybrid chunking.
- For Large-Scale Systems: Balance between efficiency and context using recursive or subdocument chunking.
Best Practices for Implementing Chunking in RAG
- Monitor Chunk Sizes: Ensure chunks stay within the token limits of your language model.
- Preserve Meaning: Avoid splitting sentences or logical units arbitrarily.
- Optimize Retrieval: Use efficient indexing and retrieval mechanisms suited to your chunking strategy.
- Handle Redundancy: Implement deduplication to manage overlapping content.
- Test Extensively: Evaluate different strategies with your specific data and queries to find the optimal approach.
- Leverage Metadata: Enhance chunks with metadata for improved retrieval relevance.
Chunking is a fundamental step in the Retrieval-Augmented Generation process, directly impacting the efficiency and accuracy of the system. Understanding the various chunking strategies and their appropriate use cases allows developers to tailor RAG systems to their specific needs. By balancing the trade-offs between context preservation, computational cost, and implementation complexity, one can choose the most suitable chunking method to enhance their language models effectively.
References
- Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems, 33.
- Jurafsky, D., & Martin, J. H. (2021). Speech and Language Processing (3rd ed.). Pearson.
- Manning, C. D., et al. (2008). Introduction to Information Retrieval. Cambridge University Press.
- OpenAI. (2023). GPT-4 Technical Report. OpenAI.
Follow us here and your feedback as comments and claps encourages us to create better content for the community.