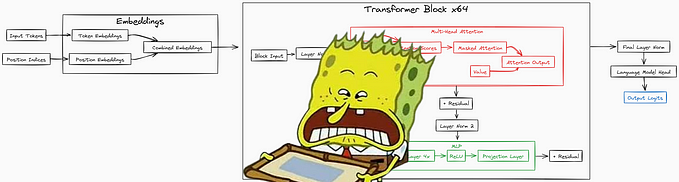
How Much GPU Memory is Needed to Serve a Large Language Model (LLM)?
In nearly all LLM interviews, there’s one question that consistently comes up: “How much GPU memory is needed to serve a Large Language Model (LLM)?”
This isn’t just a random question — it’s a key indicator of how well you understand the deployment and scalability of these powerful models in production.
When working with models like GPT, LLaMA, or any other LLMs, understanding how to estimate the required GPU memory is essential. Whether you’re dealing with a 7B parameter model or something significantly larger, correctly sizing the hardware to serve these models is critical. Let’s dive into the math that will help you estimate the GPU memory needed for deploying these models effectively.
The Formula to Estimate GPU Memory
To estimate the GPU memory required for serving a Large Language Model, you can use the following formula:
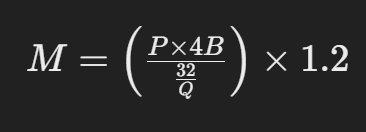
- M is the GPU memory in Gigabytes.
- P is the number of parameters in the model.
- 4B represents the 4 bytes used per parameter.
- Q is the number of bits for loading the model (e.g., 16-bit or 32-bit).
- 1.2 accounts for a 20% overhead.
Want to find out correct and accurate answers? Look for our LLM Interview Course
- 100+ Questions spanning 14 categories
- Curated 100+ assessments for each category
- Well-researched real-world interview questions based on FAANG & Fortune 500 companies
- Focus on Visual learning
- Real Case Studies & Certification
50% off Coupon Code — LLM50
Link for the course —
Breaking Down the Formula
Number of Parameters (P):
- This represents the size of your model. For instance, if you’re working with a LLaMA model that has 70 billion parameters (70B), this value would be 70 billion.
Bytes per Parameter (4B):
- Each parameter typically requires 4 bytes of memory. This is because floating-point precision usually occupies 4 bytes (32 bits). However, if you’re using half-precision (16 bits), the calculation will adjust accordingly.
Bits per Parameter (Q):
- Depending on whether you’re loading the model in 16-bit or 32-bit precision, this value will change. 16-bit precision is common in many LLM deployments as it reduces memory usage while maintaining sufficient accuracy.
Overhead (1.2):
- The 1.2 multiplier adds a 20% overhead to account for additional memory used during inference. This isn’t just a safety buffer; it’s crucial for covering memory required for activations and other intermediate results during model execution.

Example Calculation
Let’s consider you want to estimate the memory required to serve a LLaMA model with 70 billion parameters, loaded in 16-bit precision:
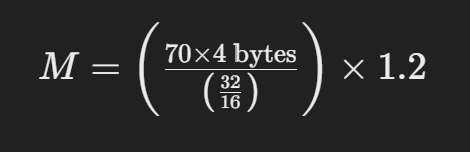
This simplifies to:
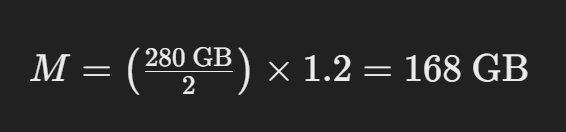
This calculation tells you that you would need approximately 168 GB of GPU memory to serve the LLaMA model with 70 billion parameters in 16-bit mode.
Practical Implications
Understanding and applying this formula is not just theoretical; it has real-world implications. For instance, a single NVIDIA A100 GPU with 80 GB of memory wouldn’t be sufficient to serve this model. You would need at least two A100 GPUs with 80 GB each to handle the memory load efficiently.

By mastering this calculation, you’ll be equipped to answer this essential question in interviews, and more importantly, avoid costly hardware bottlenecks in your deployments. Next time you’re sizing up a deployment, you’ll know exactly how to estimate the GPU memory needed to serve your LLMs effectively.
AgenticRAG with LlamaIndex Course
Look into our AgenticRAG with LlamaIndex Course with 5 real-time case studies.
All previous coffee break concepts
Look for all of our volumes of coffee break concepts:
Your feedback as comments and claps encourages us to create better content for the community.